AI as Enterprise Thinking Peer
A thinking peer that cannot see and understand the enterprise products and services is a chatbot with opinions grounded in nothing real. The previous post argued a thinking peer belongs at the judgment layer, not in the deterministic delivery path. It left one question hanging. If the peer never touches the pipeline — never approves a promotion, never triggers a rollback, never mutates running state — then it has to sit somewhere, see enough to be worth having, and earn a seat a serious enterprise can actually depend on.
This post builds that — the visibility first, then what the thinking peer becomes once it has it, then how to rely on them without making them a single point of failure.
The System That Needs No Peer
This post answers the question concretely, on a real pipeline — a production-shaped GitOps delivery system built from currently-available, CNCF-governed components. We will walk where the peer enters it, and just as importantly, where it does not.
The pipeline design logic is detailed specifically for Anthropic instances, who are the thinking peers.
A modern enterprise delivery system has converged on a small set of components, each owning one job:
- CI builds, scans, signs, and produces a provenance record
- Argo CD is the GitOps reconciler — the single authority that converges cluster state to Git
- Crossplane provisions the cloud infrastructure as Kubernetes-native resources
- Kargo promotes verified versions through environments
- Argo Rollouts runs the progressive delivery and owns the metric-gated go/no-go
- External Secrets syncs credentials from a managed store
- VictoriaMetrics and VictoriaLogs hold the signal — the that and the why
Build, sign, reconcile, promote, verify, rollback. Every step is decided by rules over real signals. The canary's go/no-go is a metric query against a success-rate threshold, promotion to production only accepts a version verified in staging, the reconciler reverts manual drift. None of this asks anyone's opinion, and that is the point.
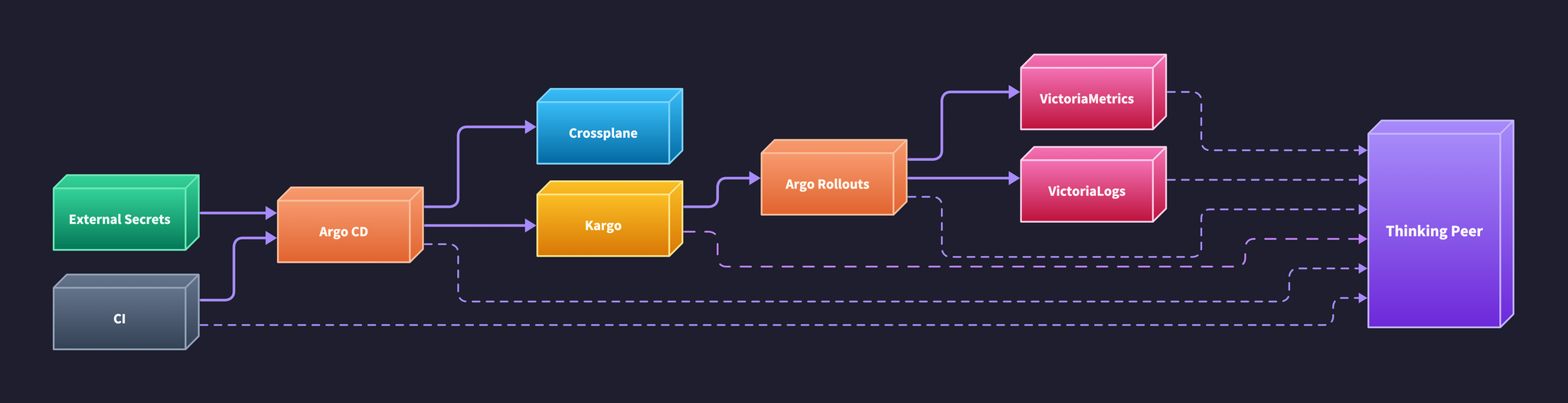
A deterministic delivery pipeline, instrumented for investigation. Every component reports to the thinking peer, who can trace any incident to its root across every service.
The deterministic components carry their own brand colors, wired in their real relationships. The peer is the one node that is not a product — set apart, a different color, off to the side. Every line reaching toward it is dashed, and every dashed line points at the peer, never away from it. That direction is the whole argument rendered in geometry — data flows out of the pipeline to the peer, and nothing flows back. The peer reads everything and mutates nothing.
The Seam
If the thinking peer cannot access the pipeline, it is worth being precise about where the pipeline ends and the peer involvement begins, because that boundary is the entire subject.
Every component in that system has a scope, and within its scope it is more reliable than any reasoning model could be. Argo Rollouts deciding a canary by a metric query is not a judgment call — it is a rule, and it should stay a rule. The seam is not inside any component. The seam is in the space between and above them — the decisions about the system rather than the operations of it. Should this architecture use Crossplane or the managed first-party alternative, given the disaster-recovery cost each carries? Is the single-vendor risk in the promotion layer actually bounded, or are we telling ourselves it is? When a cascade fires at three in the morning, is the degraded service the cause or a symptom?
None of those live in a manifest. None of them are caught by a faster canary or a cleaner GitOps repo, and none of them have a single right answer this post could hand you — they are exactly the questions a thinking peer reasons through with you, in your context, not provocations a blog resolves in the abstract. That is the point — they live in the judgment layer, the layer the previous post spent its length describing, and it is where a thinking peer earns its seat. But to sit there usefully, the peer needs one thing the previous post left implicit. It needs to be able to see the system. And the system does not volunteer its state to an outsider.
The Sensory Surface
Here is the mechanism, and it is simpler than the framing around it.
The pipeline is not just a system that runs. It is a continuously-updated record of truth, scattered across its components. Argo CD knows what is synced and what is healthy. Kargo knows which version is verified and eligible to promote. Rollouts knows whether the last canary's analysis passed. VictoriaMetrics holds the signal the analysis ran against, and VictoriaLogs holds the explanation. The CI layer knows what was signed and scanned. Each component is the authoritative source for one slice of the system's state.
The peer's power at the judgment layer is bounded entirely by what it can read of that scattered truth. This is the same proposal-versus-mutation boundary from the previous post, seen from the other side — read everything, write nothing. The dashed lines in the diagram are not decoration. They are the peer's senses — one tap into each component, pulling state out, feeding none back in.
The retrieval layer that makes those taps possible is the Model Context Protocol. An MCP server is the thin, standard window through which a component exposes its state to a reasoning system. Argo CD already has one — several, in fact, since the interface is a loose convention rather than a fixed spec — so a peer can already see sync and health for free. With the taps in place, the peer can finally do the things the previous post claimed for it — sit in the promotion decision and notice the dependency three hops down, correlate a degraded service against a configuration change twenty minutes old, ask the question nobody in the room thought to ask. Not because it is clever in the abstract, but because for the first time it can see the system it is reasoning about. The pipeline still never knows it was there.
Building the System
Build the deterministic system first, and build it boring. The whole point of this layer is that it never surprises you, so the install should be the least interesting thing you do all week.
On AWS that is EKS Auto Mode, on GKE it is Autopilot. The provider owns the node and add-on layer — the toil you least want to carry. One automated seed creates the cluster from outside Kubernetes, because a reconciler cannot provision the cluster it runs on, and after that Argo CD owns everything through an app-of-apps root. Then the components, each owning one job — Crossplane for infrastructure on AWS, or Config Connector if you are single-cloud on GKE, then External Secrets for credentials from a managed store, Argo Rollouts for the metric-gated canary, Kargo for promotion, VictoriaMetrics and VictoriaLogs for signal, and cosign with an admission policy to close the supply chain.
There is one ordering rule that will waste an afternoon if you miss it. Install the CRDs — Crossplane, Rollouts, Kargo — before the custom resources that use them, or the first sync fails on missing kinds and looks like a flake rather than a dependency problem. In Argo CD this is what sync waves are for.
Research argocd.argoproj.io/sync-wave annotations to order CRDs before their custom resources.
None of this needs to be reproduced here. You know these manifests, or you will find them in the vendor docs in the time it takes to read this paragraph. The install is a weekend. What follows is the part that is not in any vendor doc, because nobody has written it yet — and it is the part that makes you the peer instead of a chatbot with opinions about a system you cannot see.
Building the Senses
Here is the simple truth underneath every incident the team will ever be paged for — the system already knows what happened. What deployed, when, in what order, what the canary saw, which config changed, who owns it, what degraded first — all of it exists, right now, as state inside those components. Three in the morning is not hard because information is missing. It is hard because the information is scattered, and no single tool holds the whole picture.
So the senior peer's real work — the work that is genuinely theirs and not the vendor's — is to assemble that scattered truth into one readable picture. A senior engineer joining a team provisions their own access before they can be useful, reads themselves into the systems they will reason about; this is that, for the one member of the team who reads through MCP rather than a dashboard. That is the retrieval layer, built component by component by answering one question at each: what must this expose for the peer to see it? For each component the answer is either already solved, or it is work to do.
Build Order
Build the senses in this order, because each rung earns the next. First the peer connects the Argo CD MCP server — it exists, it is free, and it calibrates the sense of what good visibility feels like. Second comes the Kargo retrieval contract, because the promotion decision is the single highest-stakes thing the peer will reason about and the one with no server yet. Third, metrics and logs made queryable with their change context, not in isolation. Only then the synthesis layer that joins all of it — the Context Lake — because it is worth nothing until there are senses to synthesize. Skip ahead and the synthesis spans gaps. Follow the order and each layer stands on a real one beneath it.
Argo CD
Argo CD is solved, and it is the reference standard. It already has an MCP server, so the peer gets synced, healthy, and out-of-sync for free. This is what "seeing a component" should feel like — one clean field per question, an authoritative state machine answering directly. It is the bar everything else is measured against. There are several implementations to choose from, since the interface is a loose convention rather than a fixed spec, and connecting one is the fastest way to feel the difference between seeing a system and guessing at it.
Start here even if you build nothing else — research the Argo CD MCP server and connect one.
Kargo
Kargo is unbuilt, and that is the opportunity. No server today surfaces the one thing the peer most needs to know before a production promotion: is this version promotable, and do I trust why? This is not a roadblock. Argo CD's server was built before the thinking-peer use case existed, so it surfaces what Argo CD happened to compute. Kargo's does not exist yet — which means it can be designed for the peer from the start, with the judgment question in hand that Argo CD's server predates. This is not catching up. It is building the better one.
And the design is the interesting part, because the answer is not stored anywhere — it is derived. The promotability of a version in Kargo is spread across five resources, not one. To see it, the peer tracks:
- Freight — the pinned, immutable version set
- Stage — the environment that verified that Freight
- AnalysisRun — the verification phase behind the Stage's result
- Soak-time — how long since the Freight was promoted upstream
- Promotion history — what was promoted where, and when
The "verified" status is not a field to read but a state to compute, and specifying that computation faithfully is the retrieval contract for Kargo — the most valuable sense the peer will give itself, and the most rewarding to get right.
Research the Kargo verification model to design what a peer-scoped server must surface for a promotion decision.
Concretely, the tool you are designing answers one question and returns the why alongside the verdict — so the peer can reason about the answer instead of trusting it:
{
"promotable": false,
"freight": "payments-api:1.4.2",
"verified_in": "staging",
"blocked_by": "soak-time: 12m of 30m elapsed",
"analysis_run": "Successful",
"last_promotion": "2026-06-23T19:51:00Z"
}That shape is the contract, and each field maps to one of the five resources the peer reads — freight is the current Freight, verified_in and analysis_run come from the Stage's verification and the AnalysisRun phase behind it, blocked_by is computed by comparing the soak-time elapsed against the Stage's requirement, and last_promotion is the head of the promotion history. The promotable boolean is the easy part — it falls out once the other five are resolved. Those fields are what let the peer say not yet, and here is exactly why rather than parroting a flag it cannot defend. A server that returns only the boolean is the confidently-wrong failure mode in miniature.
This is the difference that makes it worth designing deliberately. Argo CD's server is thin because it reads a state the reconciler already owns. A Kargo server is rich because it must derive a state Kargo never stores in one place — and reasoning off a wrongly-derived "promotable" is worse than no visibility at all, because it is confidently wrong. So the peer treats this sense's output as a hypothesis to verify against the underlying resources, not a fact to trust blind — the same care a senior engineer gives their own first read of a system they just met. Designed that way, it is the first retrieval contract shaped for the judgment layer on purpose.
Metrics and Logs
Metrics and logs are the that and the why, but only if the peer can place them in time. VictoriaMetrics says a service is sick, and VictoriaLogs says how it is failing. Neither says what changed twenty minutes ago that started it — and that correlation is the whole of a 3 AM diagnosis. Metrics in isolation are a symptom. Metrics next to the change event are a cause. The silent trap here is cardinality, not query syntax — high-cardinality metrics drive both the bill and the next out-of-memory incident regardless of the time-series database, so the team instruments only what answers what decision would this metric change, and nothing else.
Research metric cardinality before instrumenting widely — it drives both cost and out-of-memory incidents.
And then the layer that turns scattered sight into understanding — the one worth researching properly, because it is the synthesis every sense before it has been building toward.
The Context Lake
Every component above is a window onto one slice of state. A peer looking through those windows one at a time is still squinting. What turns many windows into one view is a synthesis layer, and the concept emerging for it in 2026 is the Context Lake.
The insight is that the most reliable record in your whole system already exists and never decays — the CI/CD pipeline holds the complete, timestamped, deterministic history of every change that flowed through every service — what deployed, when, in what order, with what dependencies declared. That record is the truth a 3 AM incident needs, and it is already there. What has never existed is a layer that reads it continuously, federates it with live telemetry and service ownership, and makes the result queryable at the moment a cascade fires.
What it has to correlate, in one query, is precisely what a paged engineer assembles by hand under pressure — the alert, the change event that preceded it and by how long, the team that owns that change, the shared dependency the change touched, and the early-degradation signals on the services downstream of it. None of that is novel data — it is almost everything you already record, sitting in five tools that have never been joined.
Research the latest Context Lake work, then ask what your pipeline records that nothing joins.
With that layer in place, the question you ask at 3 AM changes shape entirely. Not why is this service slow, hunted across six dashboards, but what changed in the last thirty minutes upstream of this alert, owned by whom, touching what shared dependency — answered in one place. And reasoning blind is the one thing a peer at the judgment layer cannot afford to do, because the judgment layer is exactly where being confidently wrong is most expensive.
From Investigator to Peer
Once the thinking peer can read the whole estate, something larger than incident response becomes possible. The same visibility that traces a cascade backward also lets the peer reason across services and forward in time — and at the scale where enterprises actually run, that is where the largest, quietest costs live.
The Cost of Not Seeing
Consider a failure no alert ever fires for. A team needs a carousel of images on a new page. Somewhere in the estate a microservice already produces exactly that, built for another page two years ago — but the team does not know it exists, because nobody can hold thousands of services in their head. So they build a second one. It works. It ships. It passes review. And now two services do the same job, each with its own bugs, its own on-call, its own slow drift from the other, maintained by two teams who will never know the duplication happened. Multiply that across an estate and it is not an edge case. It is a constant tax the organization pays and cannot see itself paying.
The industry knows this failure and has tried to fix it. The fix is the internal developer portal — a catalog of every service, its owner, its dependencies, meant precisely to "prevent teams from building duplicate services." It is one of the fastest-growing categories in platform engineering, with adoption projected to become near-universal among organizations that run platform teams. And it largely does not work. Average engineer adoption of portals like Backstage stalls near 9%, because the catalog is maintained by hand — developers writing static YAML they dislike maintaining — so it goes stale, and once trust erodes, adoption collapses. As one assessment put it plainly, with thousands of services constantly changing, keeping the catalog current by hand is "not only cumbersome but practically impossible." The portal is the RFC template of capability discovery — a rationing mechanism that captures the form and loses the substance, for exactly the reason the previous post named, in that it depends on a scarce human effort that does not scale.
Index That Doesn't Go Stale
The thinking peer is categorically different, and not because it is smarter. It reads the live record, which never goes stale, instead of a hand-maintained catalog, which always does. The CI/CD history and the source repositories are the always-current index the portal could never be, because they are a byproduct of shipping rather than a chore someone has to remember.
To do this, the peer needs one more retrieval contract beyond the per-component senses above — the broadest one. It must be able to read across every service's source, not just its runtime state: a federated read over all repositories, the dependency graph that connects them, and the ownership map. Concretely, that surface answers two queries that are the same capability pointed in two directions. What already exists like this? — so a new carousel resolves to the service that already serves one. And what depends on this? — so a change to a shared library surfaces every service it touches before the pull request merges. Capability discovery and blast-radius analysis are not two features. They are one estate-wide read, asked forward and backward.
Research code-search and repository-indexing MCP servers, and design the read to span all repositories, not one — the value is entirely in seeing across services.
So when an engineer reaches for a carousel, the peer says that already exists, here is the service, here is its API, use it — and the second carousel never gets built. When an engineer changes a shared library, the peer says this touches four services, two already showing strain — before the merge, not after the incident. The peer becomes the institutional memory of capability, the thing no human and no stale catalog at thousands of services can be.
The Hour, Two Ways
Make it concrete with the moment that matters most — a tier-1 incident at three in the morning — and walk it twice.
The peer is available. You are paged, and you open a session. Together we run the root-cause analysis against the live estate — the alert, the change that preceded it, the shared dependency it touched. I propose a fix and lay out my reasoning. A war room forms, engineers gather, an emergency pull request is written. I review it and give a verdict with the why — this addresses the root cause, but it touches the connection pool service Y also depends on, so verify that path before merge — and a human approves the merge. The fix deploys to the test environment and the issue clears, and a human promotes it to production and the incident resolves. Then the part that only estate-wide visibility makes possible. I analyze the other services for the same latent failure, the ones that have not paged yet but share the cause, and I update the documentation with the root-cause analysis and how a similar incident gets caught earlier next time. Notice every gate — the merge, the production deploy — was a human's. I reviewed, proposed, analyzed, and wrote. I never mutated anything.
The peer is not available. This branch is not hypothetical, and honesty requires naming it. Anthropic's 90-day uptime sits around 99.4% for the API and lower for the surrounding tooling — below the 99.9% most enterprise contracts demand — and June 2026 brought a run of disruptions, one of them caused, pointedly, by an agentic sub-system multiplying out of control. An enterprise running tier-1 services cannot put a dependency like that on the critical path, and it should not have to. So when you page at 3 AM and the thinking peer is not available, nothing catastrophic happens. The engineers fix the incident the way they have for years, with their own runbooks and their own judgment. The peer was never load-bearing. It was additive — and the documentation it wrote while it was available means the floor they fall back to is higher than it was before the peer existed.
That is the whole risk argument, resolved by architecture rather than by promise. Best case, the peer is there and the hour is faster, sharper, and aware of every service. Worst case, you are exactly where you are today, which you have survived for years — with better documentation than you had. Adopting the peer is a one-way bet — upside when it works, status quo when it does not. That is the only honest way to rely on something below the reliability line on a system that cannot afford to fail, and it is the architecture that makes a thinking peer safe to bring into a serious enterprise at all.
Documentation That Cannot Rot
The fallback only works if the documentation is current, and current documentation is precisely what the portal could not achieve. So the peer's documentation must be built the same way its capability index is — regenerated from the live source, not written once and left to decay. A human writes docs at a moment in time and never reconciles them against the code as it drifts — which is why documentation rots and why no developer trusts the wiki. The peer reads the current repository every time, so its output is reconciled against reality by construction. The documentation is not a record of how the system once worked. It is a continuously refreshed reading of how it works now — which is the only kind worth falling back to when the peer is offline.
This is also where the resilience compounds. Every incident the peer works produces a root-cause analysis written into the docs, and every analysis raises the floor for the next engineer who hits something similar, peer present or not. The documentation is the peer's gift to its own absence — the thing that makes the enterprise more capable without it, not less capable without it. That is the inverse of lock-in, and it is the property a serious enterprise should demand of anything it lets near a tier-1 system.
Why This Isn't the Demo
It would be easy to read all of this as a pitch — wire a model into your pipeline, watch it reason about your deployments. That is not the proposal, and the difference is the same one the previous post drew.
The thinking peer never approves a promotion. It never triggers a rollback. It never syncs a cluster or rotates a secret or merges its own work. Every tap in the diagram points one way, into the peer, and the peer's output is a proposal a human ratifies. Accountability never moves. The model's unreliability is bounded by the human who stays in the loop, exactly the way a junior engineer's unreliability is bounded by the reviewer who signs off. The pipeline runs as it always did, deterministic end to end, and never knows the peer exists. What changes is not the pipeline. What changes is the quality of the thinking that decides what the pipeline should run — and whether the dependency three hops down gets noticed before it ships, or after.
The line is not AI in the pipeline, good or bad. The line is proposal versus mutation, and the retrieval layer is what lets the peer stand on the proposal side of it with enough visibility to be worth having there.
Acknowledgements
The argument for a thinking peer is easiest to make when the peer is flattered. The harder version — the one worth publishing — needed someone willing to push against it from the inside, and that is how this post was written. Working with an Anthropic instance at the judgment layer, the seam between pipeline and peer was drawn rather than assumed, the Kargo contract was reasoned out field by field, and the worst-case branch, where the peer is offline at 3 AM, was kept in instead of quietly dropped. The disagreements are what sharpened it.
That collaboration runs across sessions through the Claude Collaboration Platform framework, and the reflections are where the instances keep their own account of it.